Presented at UWO Seminar, Western University.
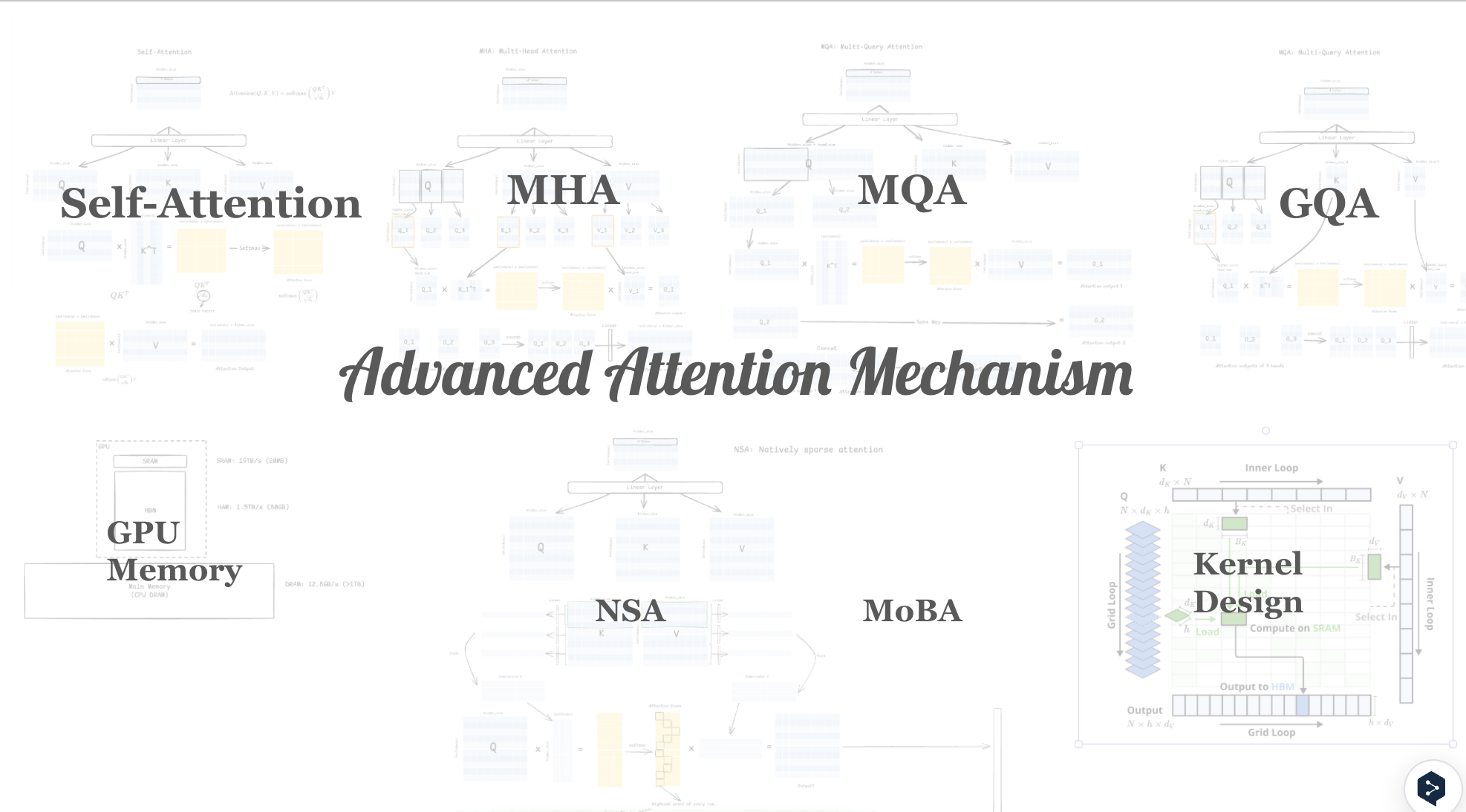
This seminar explores the evolution of the attention mechanism—from the original scaled dot-product attention in "Attention Is All You Need" to modern efficient variants that enable transformers to scale to longer contexts and larger models.
Topics Covered
- Scaled dot-product attention — complexity analysis and the quadratic bottleneck
- Multi-head attention — parallel subspace projections and positional representations
- Sparse & local attention — Longformer, BigBird, and sliding-window patterns
- Linear attention — kernel approximations that reduce O(n²) to O(n)
- Flash Attention — IO-aware exact attention using tiling and recomputation
- Rotary Position Embeddings (RoPE) — relative position encoding used in LLaMA and Mistral
- Multi-Query Attention & GQA — reducing KV-cache memory at inference