Cuttlefish: Instruction-Aware Adapters Let LLMs Focus on What Matters in 3D Entities
ICML 2026
Situation: Multimodal LLMs that process 3D structural entities allocate a fixed, equal token budget to every position — blind to structural complexity and query intent. Task: Build a unified LLM that scales its structural representation to both entity size and what the query is actually asking. Action: Designed an entropy-guided smart adapter that focuses on the instruction-relevant parts of 3D entities, dynamically allocating token budgets and injecting geometric evidence directly into the language model. Result: Achieves top-1 on 17 out of 18 QA benchmarks across heterogeneous entity types, making LLM-assisted structural understanding an operational reality.
Background & Challenge
Two failure modes that limit LLM reasoning about 3D structures:
1. Geometry-blind inputs cause unreliable outputs. When LLMs reason about 3D entities from sequence-only representations, they produce geometric descriptions — bond angles, spatial distances, functional groups — that are not grounded in actual 3D structure. Without explicit coordinates, these errors are undetectable.
2. Fixed-budget connectors lose structural detail. Standard connectors compress structural inputs into a fixed number of tokens regardless of entity complexity. Large entities are over-compressed and lose critical features; simple entities waste token capacity. A rigid budget cannot serve heterogeneous entities of varying scale.
Methodology
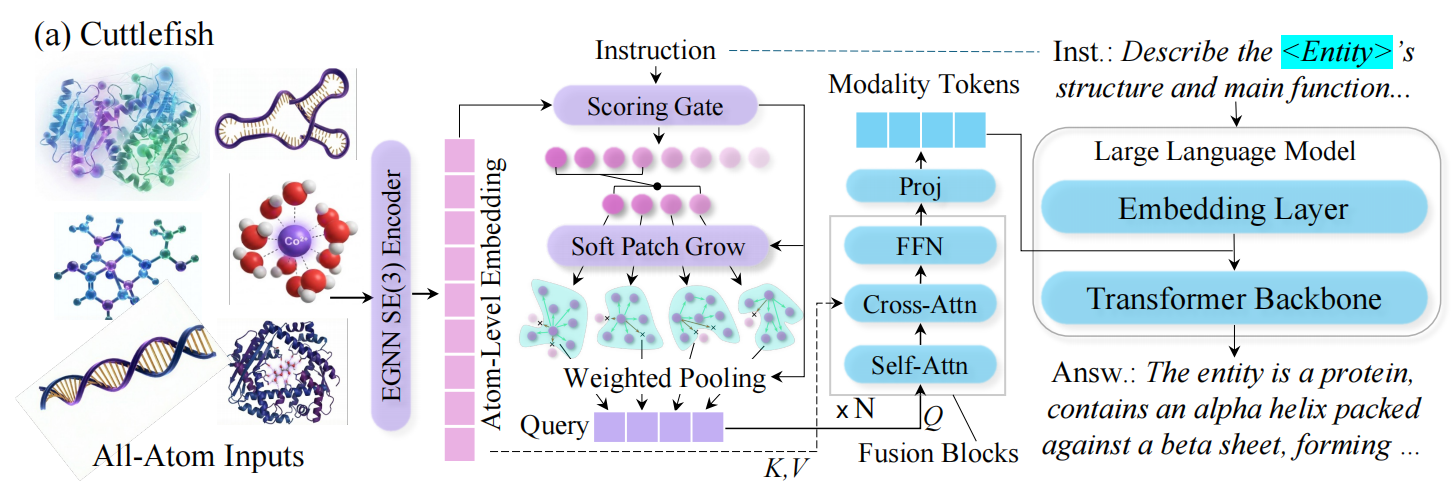
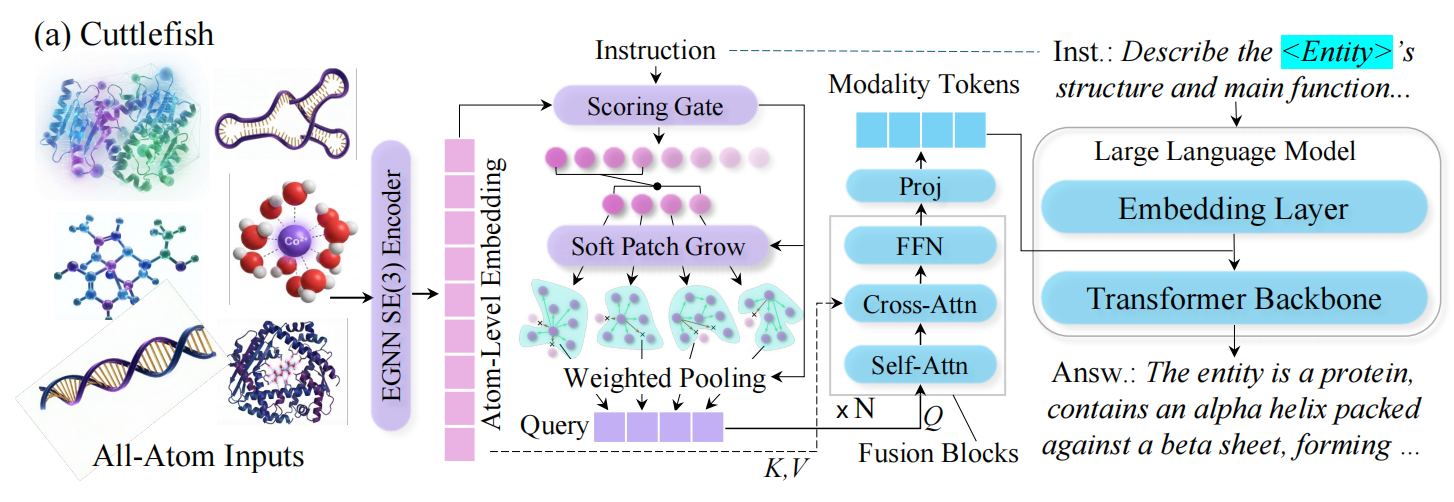
Instruction-Aware Token Allocation
Instead of assigning a fixed token budget to every entity, we score each position by its relevance to the current instruction. The highest-scoring positions become anchor points that expand to cover their local structural neighborhood. More complex or instruction-critical entities naturally receive more patches — giving the model more tokens where it needs them and fewer where it doesn't.
Ablation: removing instruction-guided scoring causes a 14.0% performance drop; replacing variable patches with fixed-size patching causes a 10.5% drop.
Geometry Injection
The patch tokens are then used to retrieve high-resolution geometric cues from the full entity representation. These cues are inserted directly into the language model's input token sequence — making 3D geometry a first-class input to the LLM rather than a preprocessed summary.
Ablation: removing the geometry retrieval step causes a 21.0% drop; replacing the full connector with a standard fixed-budget connector causes a 43.2% drop — the largest single-component degradation.
Why Multimodal Training Works
Training across diverse entity types consistently outperforms single-modality training. Cross-entity transfer provides a systematic boost — different entity types reinforce each other's structural understanding, validating the unified training design.
Results
Empirical Performance
Comprehensive evaluation across standard benchmarks:
| Benchmark | Tasks | Cuttlefish Top-1 |
|---|---|---|
| Mol-Instructions (molecules) | 15 tasks | 14/15 metrics ranked #1 or #2 |
| Mol-Instructions (proteins) | 5 tasks | 5/5 tasks ranked #1 |
| DNA-Chat | 18+ tasks | Top-1 average |
| RNA-QA | QA tasks | State-of-the-art |
| GEO-AT avg (Llama-3.1 backbone) | METEOR / BERTScore | 0.428 / 0.864 (vs. 0.186 / 0.694 sequence-only baseline) |
Cuttlefish consistently outperforms both modality-specific baselines and general LLMs across all entity types — demonstrating that unified structure-grounded reasoning surpasses single-domain specialists.
Scaling stability. Unlike fixed-budget models that degrade for large entities, Cuttlefish achieves its greatest gains in the high-complexity regime, directly attributable to adaptive token budgets growing sub-linearly with entity size.
Field Contribution
Cuttlefish addresses two gaps that prior work had not closed simultaneously: adaptive token budgeting for heterogeneous entity complexity and geometry injection for reliable structural reasoning. The connector design is backbone-agnostic (Llama, Qwen, Mistral, GLM), and we introduce GEO-AT — the first all-atom instruction dataset spanning diverse entity types with 3D coordinate annotations — making Cuttlefish an immediately usable foundation for structure-grounded multimodal LLM research.
Open-Source Access
Cuttlefish is fully open-sourced. All assets are freely available for research and downstream use:
| Asset | Link |
|---|---|
| Paper | arXiv 2602.02780 |
| Code | github.com/zihao-jing/EntroAdap |
| Pretrained LLM | zihaojing/Cuttlefish |
| Graph Encoder | zihaojing/Cuttlefish-Encoder |
| SFT Instruction Data | zihaojing/Cuttlefish-SFT-Data |
| Encoder Pretraining Data | zihaojing/Cuttlefish-Encoder-Data |
Quick Start
pip install -r requirements.txt
cd /path/to/cuttlefish
source env.sh
Load Pretrained Model
from huggingface_hub import snapshot_download
from src.models.octopus import OctopusModel
local_dir = snapshot_download(repo_id="zihaojing/Cuttlefish")
encoder_dir = snapshot_download(repo_id="zihaojing/Cuttlefish-Encoder")
Run Inference
source env.sh
bash scripts/inference/run_inference.sh
from scripts.inference.run_inference_example import run_inference
results = run_inference(
checkpoint_path="zihaojing/Cuttlefish",
input_file="your_data.parquet",
output_dir="outputs/results.jsonl",
)
For full documentation, data format specs, and training scripts, see the GitHub README.
Citation
@article{jing2026cuttlefish,
title = {Cuttlefish: Scaling-Aware Adapter for Structure-Grounded LLM Reasoning},
author = {Jing, Zihao and Zeng, Qiuhao and Fang, Ruiyi and Li, Yan Yi and
Sun, Yan and Wang, Boyu and Hu, Pingzhao},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning (ICML)},
year = {2026},
url = {https://arxiv.org/abs/2602.02780}
}
Contact
Zihao Jing (first author) — zjing29@uwo.ca
Pingzhao Hu (corresponding author) — phu49@uwo.ca
Questions, collaborations, or requests to use Cuttlefish as a baseline? We're happy to help — reach out anytime.