Piccolo-GPT: Unified Training Lets a Single LLM Power Both Retrieval and Generation
SenseTime Research 2024
Situation: RAG systems require two separate models — a dedicated embedding model for retrieval and a generative LLM for response — because their training objectives are mutually exclusive under standard fine-tuning. Task: Train a single LLM backbone that performs high-quality retrieval embedding and fluent text generation simultaneously, without degrading either capability. Action: Designed a two-stage curriculum that first establishes strong generative representations, then jointly optimizes a combined embedding-generation objective via a task-switching mechanism — so the same model weights handle both roles. Result: Achieves top-10 on CMTEB (score 68) while retaining full generation quality, enabling a single model to power both the retrieval and generation stages of a RAG pipeline.
Background & Challenge
Building a unified retrieval-and-generation model faces two fundamental conflicts:
1. Dual-system overhead in RAG. Production RAG systems need a dedicated embedding model for document retrieval and a separate LLM for answer generation. This dual-model setup doubles inference infrastructure, increases latency, and complicates serving — a substantial cost at scale.
2. Objective conflict in joint training. Embedding training optimizes a contrastive geometry — pulling similar texts together, pushing dissimilar ones apart. Generative training optimizes next-token prediction, which does not shape representation geometry the same way. Naive joint training causes one objective to dominate and suppress the other, making it impossible to maintain both capabilities simultaneously.
Methodology
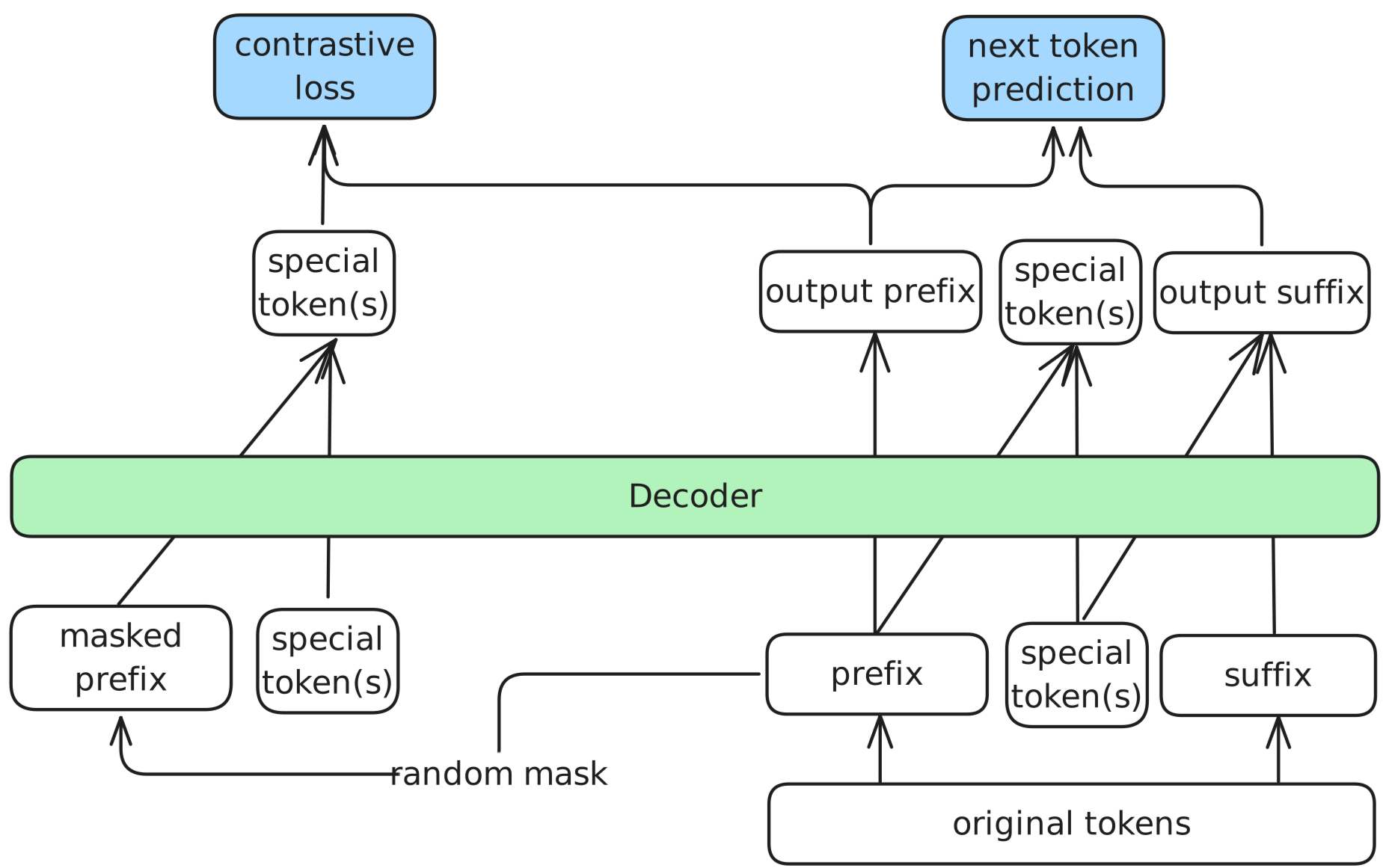
Mixed Training Objective
The model is trained on both tasks using a weighted combination of two losses: a generative cross-entropy loss for text generation, and a contrastive loss that pulls semantically similar texts together in embedding space. The two weights balance how much each objective contributes, preventing either from overwhelming the other.
Two-Stage Curriculum
Training proceeds in two stages to prevent early objective conflict. The backbone is first trained on large-scale text with the generative objective alone, establishing stable semantic representations. Both objectives are then applied jointly on labeled instruction and retrieval data — with the backbone already stable enough to resist the contrastive signal distorting generation quality.
Task-Switching Token
A dedicated <|embed|> token signals the model to switch to embedding mode. When appended to an input, the model outputs a fixed-length vector from its final hidden state instead of generating text — zero architectural overhead, same forward pass.
def egtlm_instruction(instruction):
return (
"<|user|>\n" + instruction + "\n<|embed|>\n" if instruction
else "<|embed|>\n"
)
Results
Empirical Performance
Evaluated on CMTEB (Chinese Massive Text Embedding Benchmark):
| Model | CMTEB Score | Params |
|---|---|---|
| EGTLM-Mistral7b | 68 (top 10) | 7B |
| EGTLM-Qwen1.5-1.8B | competitive | 1.8B |
| Piccolo2 (same group) | 70.95 | 300M |
EGTLM-Mistral7b reaches top-10 while retaining instruction-following and generation quality — no dedicated embedding model in the same tier supports both capabilities from a single set of weights.
Field Contribution
Piccolo-GPT demonstrates that embedding and generation objectives are not fundamentally incompatible — a single LLM with appropriate loss weighting and a staged curriculum can match dedicated embedding models while retaining full generative capability. The design is model-agnostic (Mistral, Qwen, LLaMA) and directly applicable to production RAG systems where collapsing retrieval and generation into one model halves inference infrastructure.
Open-Source Access
EGTLM is fully open-sourced with two model variants:
| Asset | Link |
|---|---|
| Paper | arXiv 2405.06932 |
| Code | github.com/zihao-jing/EGTLM |
| Model (Mistral-7B) | zihaojing/EGTLM-Mistral7b-instruct |
| Model (Qwen1.5-1.8B) | zihaojing/EGTLM-Qwen1.5-1.8B-instruct |
Quick Start
pip install accelerate transformers datasets mteb[beir]
Load Model for Embedding and Generation
from egtlm import EgtLM
model = EgtLM(
"zihaojing/EGTLM-Qwen1.5-1.8B-instruct",
mode="unified",
torch_dtype="auto",
attn_implementation="eager"
)
queries = ["请告诉我比特币是怎样运作的?"]
embeddings = model.encode(queries, instruction="<|embed|>\n")
Run Generation
messages = [{"role": "user", "content": "请帮我写一首李白的诗"}]
encoded = model.tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
output = model.model.generate(encoded, max_new_tokens=256, do_sample=False)
print(model.tokenizer.batch_decode(output)[0])
For full training configuration and RAG integration examples, see the GitHub README →
Citation
@misc{2405.06932,
Author = {Junqin Huang and Zhongjie Hu and Zihao Jing and Mengya Gao and Yichao Wu},
Title = {Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training},
Year = {2024},
Eprint = {arXiv:2405.06932},
}
Contact
Zihao Jing (co-author) — zjing29@uwo.ca
Questions about unified retrieval-generation training, RAG system design, or EGTLM deployment? Reach out anytime.